Abstract: This tutorial will demonstrate how to use TensorLayerX's LSTM network to complete the text classification task. This is a relatively simple example that will use a network composed of an embedding layer and LSTM to complete the image classification task of the Imdb dataset.
Deep learning usually converts text, speech, etc. data into sequence data, and then uses recurrent neural networks to process them. For text data, the simplest method is to convert the text into a word vector, and then use the word vector as a sequence data.
We first need a dictionary vocabulary that contains all words, and each word has a unique ID, then we convert the text into an ID sequence, and then convert the ID sequence into a word vector sequence. Take a sentence as an example: "I love TensorLayerX", this sentence has 3 words, we can convert it into an ID sequence [1, 2, 3], and then convert the ID sequence into a one-hot word vector sequence [[1, 0, 0], [0, 1, 0], [0, 0, 1]], where each word vector has a dimension of 3, that is, there are 3 words in the dictionary.
If each sample represents a sentence or a paragraph, then B data in a batch can be seen as B sentences or paragraphs, and the length of each sentence or paragraph is T, and the dimension of each word vector in each sentence or paragraph is D, then the data in a batch can be seen as a three-dimensional data of [B, T, D].
In TensorLayerX, we provide the tlx.text.nlp module to handle text data, including converting text to word vectors, and converting word vectors to text, etc.
The IMDB dataset is a dataset used for text classification, which contains 50,000 movie reviews from the IMDB website, of which 25,000 are used for training and 25,000 are used for testing. Each review is marked as a positive or negative review.
Generally speaking, convolutional neural networks are used to handle image data tasks, and text and other sequential data tasks are generally handled by recurrent neural networks RNN (Recurrent Neural Network).
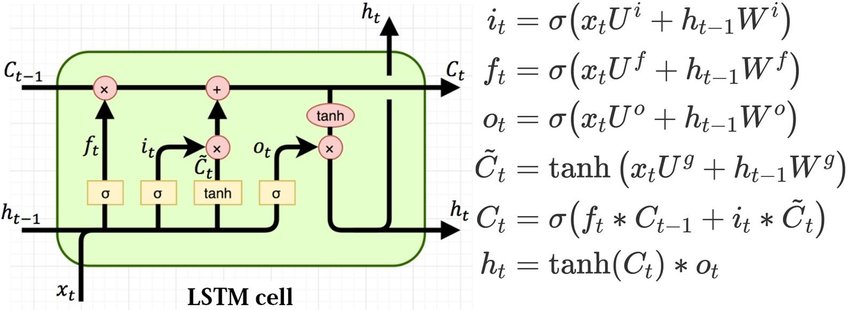
Among them, LSTM (Long Short-Term Memory) network is a kind of recurrent neural network, which is specially designed to solve the long-term dependency problem of general RNN. In the standard RNN, this repeated structure module only has a very simple structure, such as a fully connected layer using tanh as the activation function.
The RNN model in the same cell (Cell) at each time, each time using the current t and the previous t-1 input, generate the current time output, can solve a certain time sequence problem, but due to the short-term memory influence, it is difficult to pass the information from the earlier time to the later time. LSTM further simulates the process of human memory thinking, by introducing gate structures (forget, input, output three gate structures), it can learn how to remember and forget information, and can pass the sequence information down, and can also introduce the earlier information into the later time, so as to overcome the short-term memory.
This tutorial is based on TensorLayerX 0.5.6, if your environment is not this version, please refer to the official website installation first.
TensorlayerX currently supports TensorFlow, Pytorch, PaddlePaddle, MindSpore as the computing backend, and the method of specifying the computing backend is also very simple, just set the environment variable.
import os
os.environ['TL_BACKEND'] = 'paddle'
# os.environ['TL_BACKEND'] = 'tensorflow'
# os.environ['TL_BACKEND'] = 'mindspore'
# os.environ['TL_BACKEND'] = 'torch'
Import the required modules
import tensorlayerx as tlx
from tensorlayerx.nn import Module
from tensorlayerx.nn import Linear, LSTM, Embedding
from tensorlayerx.dataflow import Dataset
import numpy as np
The following code will use TensorLayerX's API to download the dataset and prepare the data iterator for the subsequent training task.
prev_h = np.random.random([1, 200, 64]).astype(np.float32)
prev_h = tlx.convert_to_tensor(prev_h)
X_train, y_train, X_test, y_test = tlx.files.load_imdb_dataset('data', nb_words=20000, test_split=0.2)seq_Len = 200
vocab_size = len(X_train) + 1
class ImdbDataset(Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
def __getitem__(self, index):
data = self.X[index]
data = np.concatenate([data[:seq_Len], [0] * (seq_Len - len(data))]).astype('int64') # set label = self.y[index].astype('int64')return data, label
def __len__(self):
return len(self.y)
train_dataset = ImdbDataset(X=X_train, y=y_train)
Next, use TensorLayerX to define a neural network that uses an embedding layer (Embedding) and an LSTM layer. The embedding layer converts the input word sequence into an embedding vector sequence, and then passes the hidden state through the LSTM. After the two linear transformation layers are composed into a classification network, the word sequence is mapped by the recurrent neural network to 2 outputs, which corresponds to 2 categories of emotions.
class ImdbNet(Module):
def __init__(self):
super(ImdbNet, self).__init__()
self.embedding = Embedding(num_embeddings=vocab_size, embedding_dim=64)
self.lstm = LSTM(input_size=64, hidden_size=64)
self.linear1 = Linear(in_features=64, out_features=64, act=tlx.nn.ReLU)
self.linear2 = Linear(in_features=64, out_features=2)
def forward(self, x):
x = self.embedding(x)
x, _ = self.lstm(x, [prev_h, prev_h])
x = tlx.reduce_mean(x, axis=1)
x = self.linear1(x)
x = self.linear2(x)
return x
打印模型结构
ImdbNet(
(embedding): Embedding(num_embeddings=20001, embedding_dim=64)
(lstm): LSTM(input_size=64, hidden_size=64, num_layers=1, dropout=0.0, bias=True, bidirectional=False, name='lstm_1')
(linear1): Linear(out_features=64, ReLU, in_features='64', name='linear_1')
(linear2): Linear(out_features=2, No Activation, in_features='64', name='linear_2')
)
Next, use the Model high-level interface to quickly start the training of the model, which will:
· Use the tlx.optimizers.Adam optimizer for optimization.
· Use tlx.losses.softmax_cross_entropy_with_logits to calculate the loss value.
· Use tensorlayerx.dataflow.DataLoader to load data and build batch.
· Use the tlx.model.Model high-level model interface to build the model for training
n_epoch = 5
batch_size = 64
print_freq = 2
train_loader = tlx.dataflow.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
optimizer = tlx.optimizers.Adam(1e-3)
metric = tlx.metrics.Accuracy()
loss_fn = tlx.losses.softmax_cross_entropy_with_logits
model = tlx.model.Model(network=net, loss_fn=loss_fn, optimizer=optimizer, metrics=metric)
model.train(n_epoch=n_epoch, train_dataset=train_loader, print_freq=print_freq, print_train_batch=True)
Epoch 1 of 5 took 1.2969748973846436
train loss: [0.6930715]
train acc: 0.546875
Epoch 1 of 5 took 1.305964708328247
train loss: [0.69317925]
train acc: 0.5078125
......
Epoch 5 of 5 took 2.8309640884399414
train loss: [0.18543097]
train acc: 0.9305111821086262
From the above example, we can see that on the Imdb dataset, using a simple LSTM neural network, TensorLayerX can achieve an accuracy of more than 93%. You can also achieve better results by adjusting the network structure and parameters.


